
自己看的记录笔记
写的很差 勿看
参考文献
https://blog.csdn.net/luoxiaolin_love/article/details/82258069
相对位置
NAACL 2018的论文
读论文读的太少了
作者认为正弦余弦位置向量效果是比可学习的更好的,因为他可以看到训练中未见到的序列长度
self attention中增加位置感知,考虑输入元素之间的成对关系 ,窗口 不用全看 多一个参与学习的矩阵
对于长度为n的,有h个attention heads的序列,通过在每个head上共享相对位置表示
why 相对位置:输入元素间的成对关系
1. Transformer
Transformer采用由堆叠编码器和解码器层组成的编码器-解码器结构。编码器层由两个子层组成:self-attention层,然后是一个位置感知的前馈层。解码器层由三个子层组成:self-attention,然后是编码器-解码器attention,然后是一个位置感知的前馈层。它使用每个子层周围的残差连接,然后再进行层归一化。解码器在其self-attention中使用掩码以防止给定的输出位置在训练期间包含关于未来输出位置的信息。
在第一层之前,在编码器和解码器输入元件中添加基于频率变化的正弦信号的位置编码。与学习的绝对位置表示相比,作者假设正弦波位置编码将帮助模型推广到训练过程中未见的序列长度,使它能够学习参加相对位置,这一性质是由作者的相对位置表示所共有的,与绝对位置表示相比,相对位置表示与总序列长度是不一致的。
残差连接有助于将位置信息传播到更高的层。
修剪最大距离还使模型能够推广到训练期间未观察到的序列长度。因此,作者考虑2k+1唯一的边缘标签
CSDN 博客
在《Attention Is All You Need》基础上,对position encodeing进行了优化。在《Attention Is All You Need》中采用的position encoding的方式,没有考虑到词与词之间的距离。因此本文提出一个位置向量表示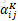
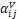
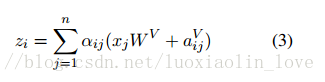
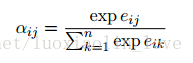
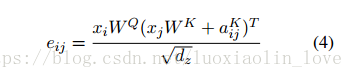
对于现行序列,本文边可以捕获输入元素之间相对位置的差异性。因为本文假设一定距离之外精确的相对位置信息在是无用的,所以只考虑最大相对位置为k的情况。这种使用j-i的形式,可以处理在训练集中没有见过的序列长度。(之前的方法应该存在这个问题,不能处理比训练数据更长的数据)

而

